
مقدمه
یکی از قابل توجه ترین قوس های قرن بیست و یکم، رشد انفجاری است که در استفاده و به کارگیری فناوری مشاهده شده است. به طور خاص تر، پیشرفت فناوری اطلاعات و ارتباطات (ICT) پایه و اساس بسیاری از نوآوری هایی بوده است که در این قرن تاکنون دیده شده است. پذیرش گسترده اینترنت برای رسانه های اجتماعی، تجارت الکترونیک، مصرف اخبار و موارد دیگر، بسیاری از زندگی روزمره و صنایع ما را در سراسر جهان بازتعریف کرده است. با توجه به پیشرفتهای فناوری اطلاعات و ارتباطات، فرصتهای هیجانانگیزی برای آنچه هنوز در راه است وجود دارد. یک فرصت دیرینه برای آینده چشم انداز شهر هوشمند است.
قرار دادن سرویسهای یادگیری عمیق با آگاهی از QoS در لبه با پیادهسازی چندین سرویس
محاسبات لبه موبایل خدمات محاسباتی فشرده را به کاربر نزدیکتر میکند تا تاخیر کمتری را به دلیل نزدیکی فیزیکی ایجاد کند. این باعث شده است که بسیاری به فکر استقرار مدل های یادگیری عمیق در لبه باشند - که معمولاً به عنوان هوش لبه (EI) شناخته می شود. سرویسهای EI میتوانند پیادهسازیهای مدل زیادی داشته باشند که QoS متفاوتی را ارائه میکنند. به عنوان مثال، یک مدل می تواند استنتاج را سریعتر از مدل دیگر انجام دهد (در نتیجه تأخیر را کاهش می دهد) در حالی که هنگام ارزیابی دقت کمتری به دست می آورد. در این فصل، قرار دادن خدمات مشترک و زمانبندی مدل خدمات EI را با هدف به حداکثر رساندن کیفیت خدمات (QoS) برای کاربران نهایی که در آن سرویسهای EI پیادهسازیهای متعددی برای ارائه درخواستهای کاربر دارند، هر کدام با هزینهها و مزایای QoS متفاوت، مطالعه میکنیم. ما مسئله را به عنوان یک برنامه خطی عدد صحیح قرار می دهیم و ثابت می کنیم که NP-hard است. سپس ثابت میکنیم که هدف معادل به حداکثر رساندن یک تابع مجموعه زیر مدولار افزایشدهنده یکنواخت است و بنابراین میتوان با حریصانه آن را حل کرد و در عین حال تضمین تقریبی (1-1/e) را حفظ کرد. سپس دو الگوریتم حریص را پیشنهاد میکنیم: یکی که از لحاظ نظری این تقریب را تضمین میکند و دیگری که از نظر تجربی عملکرد خود را با کارایی بیشتر مطابقت میدهد. در نهایت، ما به طور کامل الگوریتم پیشنهادی را برای تصمیمگیری مکانیابی و زمانبندی در سناریوهای مصنوعی و دنیای واقعی در برابر راهحل بهینه و برخی از خطوط پایه ارزیابی میکنیم. در مورد دنیای واقعی، ما مدلهای یادگیری ماشین واقعی را با استفاده از مجموعه داده ImageNet 2012 برای درخواستها در نظر میگیریم. آزمایشهای عددی ما بهطور تجربی نشان میدهند که الگوریتم حریص کارآمدتر ما میتواند به طور متوسط راهحل بهینه را با تقریب 0.904 تقریب کند، در حالی که نزدیکترین خط پایه بعدی به طور متوسط به تقریب 0.607 دست مییابد.
تصمیمات فشرده سازی و بارگذاری مشترک برای خدمات یادگیری عمیق در سیستم های لبه سه لایه
بارگذاری وظایف در زیرساخت محاسبات لبه همچنان یک چالش برای محیط های پویا و پیچیده مانند اینترنت اشیاء صنعتی است. محدودیت های منابع سخت افزاری سرورهای لبه باید به صراحت در نظر گرفته شوند تا اطمینان حاصل شود که منابع سیستم بیش از حد بارگذاری نمی شوند. بسیاری از کارها بارگذاری وظایف را مورد مطالعه قرار داده اند در حالی که در درجه اول بر اطمینان از انعطاف پذیری سیستم تمرکز کرده اند. با این حال، در مواجهه با خدمات مبتنی بر یادگیری عمیق، عملکرد مدل با توجه به از دست دادن / دقت نیز باید در نظر گرفته شود. سرویسهای یادگیری عمیق با پیادهسازیهای مختلف ممکن است مقادیر متفاوتی از دست دادن/دقت را ارائه دهند و در عین حال اجرای استنتاج بر روی آنها پیچیدهتر باشند. با این حال، تأخیر ارتباط را می توان برای بهبود کلی کیفیت خدمات با استفاده از تکنیک های فشرده سازی کاهش داد. با این حال، چنین تکنیکهایی میتوانند اثرات جانبی کاهش تلفات/دقت ارائه شده توسط سرویس مبتنی بر یادگیری عمیق را نیز داشته باشند. به این ترتیب، این کار یک مسئله بهینهسازی مشترک را برای تصمیمگیریهای بارگذاری کار در پلتفرمهای محاسباتی لبهای سهلایه که در آن تصمیمگیریها در مورد بارگذاری کار همزمان با تصمیمگیریهای فشردهسازی گرفته میشود، مطالعه میکند. هدف این است که درخواستها را با فشردهسازی بهطور بهینه تخلیه کنیم، به طوری که مبادله بین تأخیر-دقت به شدت به خطر نیفتد. ما این مشکل را به عنوان یک برنامه غیرخطی اعداد صحیح مختلط در نظر گرفتیم. به دلیل ماهیت غیرخطی آن، سپس آن را به زیرمشکلات جداگانه برای تخلیه و فشرده سازی تجزیه می کنیم. یک الگوریتم کارآمد برای حل مسئله پیشنهاد شده است. از نظر تجربی، ما نشان میدهیم که الگوریتم ما تقریباً به تقریبی 0.958 از راهحل بهینه ارائه شده توسط روش نزول مختصات بلوکی برای حل دو مشکل فرعی پشت سر هم میرسد.
چارچوبی برای شبکه های توزیع هوشمند لبه از طریق یادگیری فدرال
پیشرفتهای اخیر در پردازش دادههای توزیعشده و یادگیری ماشینی فرصتهای جدیدی را برای فعال کردن عملکردهای حساس و حساس به زمان شبکههای توزیع هوشمند به روشی ایمن و قابل اعتماد فراهم میکند. ترکیب ظهورهای اخیر محاسبات لبه (EC) و هوشمندی لبه (EI) با زیرساخت اندازهگیری پیشرفته (AMI) پتانسیل کاهش هزینه کلی ارتباط، حفظ حریم خصوصی کاربر و ارائه آگاهی موقعیتی بهبود یافته را دارد. در این فصل، ما یک نمای کلی برای اینکه چگونه EC و EI میتوانند برنامههای کاربردی مرتبط با سیستمهای AMI را تکمیل کنند، ارائه میکنیم. علاوه بر این، استفاده از چنین سیستمهایی به صورت پشت سر هم میتواند چارچوبهای یادگیری عمیق توزیع شده (به عنوان مثال، یادگیری فدرال) را برای توانمندسازی پردازش دادههای توزیع شده و تصمیمگیری هوشمند برای AMI فعال کند. در نهایت، برای نشان دادن کارایی این معماری در نظر گرفته شده، ما به مسئله نظارت بر بار غیر نفوذی (NILM) با استفاده از یادگیری فدرال برای آموزش یک معماری شبکه عصبی بازگشتی عمیق به شیوهای ۲ و ۳ لایه نزدیک میشویم. در این رویکرد، خانههای هوشمند به صورت محلی یک شبکه عصبی را با استفاده از دادههای اندازهگیری خود آموزش میدهند و تنها پارامترهای مدل آموختهشده را با اجزای AMI برای تجمیع به اشتراک میگذارند. نتایج ما نشان میدهد که این میتواند هزینههای ارتباطی مرتبط با یادگیری توزیعشده را کاهش دهد، و همچنین یک لایه فوری از حریم خصوصی را به دلیل عدم ارسال داده خام به اجزای AMI ارائه میکند. علاوه بر این، ما نشان میدهیم که FL میتواند از دست دادن مدل ارائه شده توسط یادگیری عمیق متمرکز استاندارد که در آن دادههای خام برای آموزش متمرکز ارسال میشود، از نزدیک مطابقت داشته باشد.
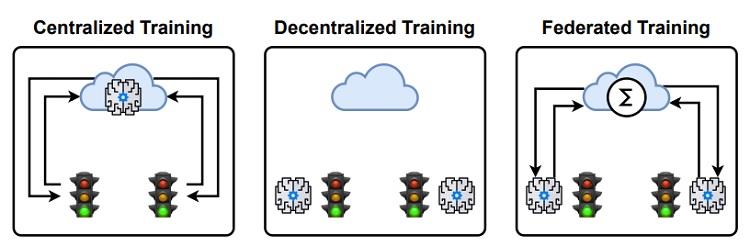
چراغهای راهنمایی هوشمند دارای لبههای هوشمند با استفاده از یادگیری تقویتی فدرال برای تبادل پاداش-ارتباطات
تراکم ترافیک یک پدیده پرهزینه زندگی روزمره است. یادگیری تقویتی (RL) یک راه حل امیدوارکننده به دلیل کاربرد آن برای حل مسائل پیچیده تصمیم گیری در محیط های بسیار پویا است. برای آموزش چراغ های راهنمایی هوشمند با استفاده از RL، مقادیر زیادی داده مورد نیاز است. رویکردهای مبتنی بر RL اخیر آموزش را در برخی از سرورهای مجاور یا یک سرور ابری راه دور انجام میدهند. با این حال، این امر مستلزم آن است که همه چراغهای راهنمایی دادههای خام خود را به یک مکان مرکزی ارسال کنند. برای سیستمهای جادهای بزرگ، هزینه ارتباط میتواند غیرعملی باشد، بهویژه اگر چراغهای راهنمایی دادههای سنگین را جمعآوری میکنند (مانند ویدئو، LIDAR). به این ترتیب، این کار آموزش را مستقیماً به چراغ های راهنمایی هدایت می کند تا هزینه ارتباط را کاهش دهد. با این حال، یادگیری کاملا مستقل می تواند عملکرد مدل های آموزش دیده را کاهش دهد. به این ترتیب، این کار ظهور اخیر یادگیری تقویتی فدرال (FedRL) را برای چراغهای راهنمایی فعال در لبه در نظر میگیرد، بنابراین آنها میتوانند از تجربیات یکدیگر با جمعآوری دورهای پارامترهای شبکه خطمشی محلی یاد گرفتهشده بهجای اشتراکگذاری دادههای خام بیاموزند، در نتیجه هزینههای ارتباطی را پایین نگه میدارند. . برای انجام این کار، ما چارچوب SEAL را پیشنهاد میکنیم که از یک نمایش تشخیصی تقاطع برای پشتیبانی از FedRL در سراسر چراغهای راهنمایی که انواع تقاطعهای ناهمگن را کنترل میکنند، استفاده میکند. سپس رویکرد FedRL خود را در برابر استراتژی های متمرکز و غیرمتمرکز RL ارزیابی می کنیم. ما مبادلات پاداش-ارتباطات این استراتژی ها را مقایسه می کنیم. نتایج ما نشان میدهد که FedRL میتواند هزینههای ارتباطی مرتبط با آموزش متمرکز را تا 36.24٪ کاهش دهد؛ در حالی که تنها شاهد کاهش 2.11٪ در میانگین پاداش (به عنوان مثال، کاهش تراکم ترافیک) در آزمایشهای ما بود.
نتیجه گیری و اظهارات پایانی
تبدیل چشم انداز جاه طلبانه شهرهای هوشمند از فانتزی به واقعیت یک کار دلهره آور است. برای دستیابی به آن به ارتباطات اطلاعاتی و زیرساخت های فناوری قوی نیاز است. محاسبات لبه یک نامزد مناسب برای پشتیبانی از بسیاری از خدمات مورد انتظار مورد نیاز برای پشتیبانی از شهرهای هوشمند است. علاوه بر این، سوق دادن راهحلهای مبتنی بر هوش مصنوعی به لبه (یعنی هوش لبه) میتواند به تبدیل دادههای جمعآوریشده در شهرهای هوشمند به دانش کمک کند و در عین حال تصمیمگیری هوشمند را به روشی آگاهانه از منابع خودکار کند.
دقت داشته باشید که این متن به کمک گوگل ترنسلیت ترجمه شده و توسط مترجمین سایت ای ترجمه ترجمه نشده است و صرفا جهت آشنایی با متن پایان نامه می باشد.
این پایان نامه خارجی در سال 2022 در دانشگاه کنتاکی برای اخذ مدرک دکتری انجام شده است. برای دانلود رایگان پایان نامه انگلیسی به صفحه پایان نامه تصمیم گیری در شهر هوشمند با هوش مصنوعی لبه در سایت ای ترجمه مراجعه نمایید.